
[ad_1]


In Brief
OpenAI announced the open-source release of WHISPER V3, a state-of-the-art model for voice recognition in multiple languages.

Artificial intelligence (AI) research company OpenAI, has taken a significant leap in the realm of speech recognition by open-sourcing its state-of-the-art model Whisper large-v3, during their Developer Day event.
This latest iteration of the Whisper model demonstrates a remarkable ability to understand and transcribe voice in a multitude of languages, broadening its applicability beyond the English-centric models of the past.
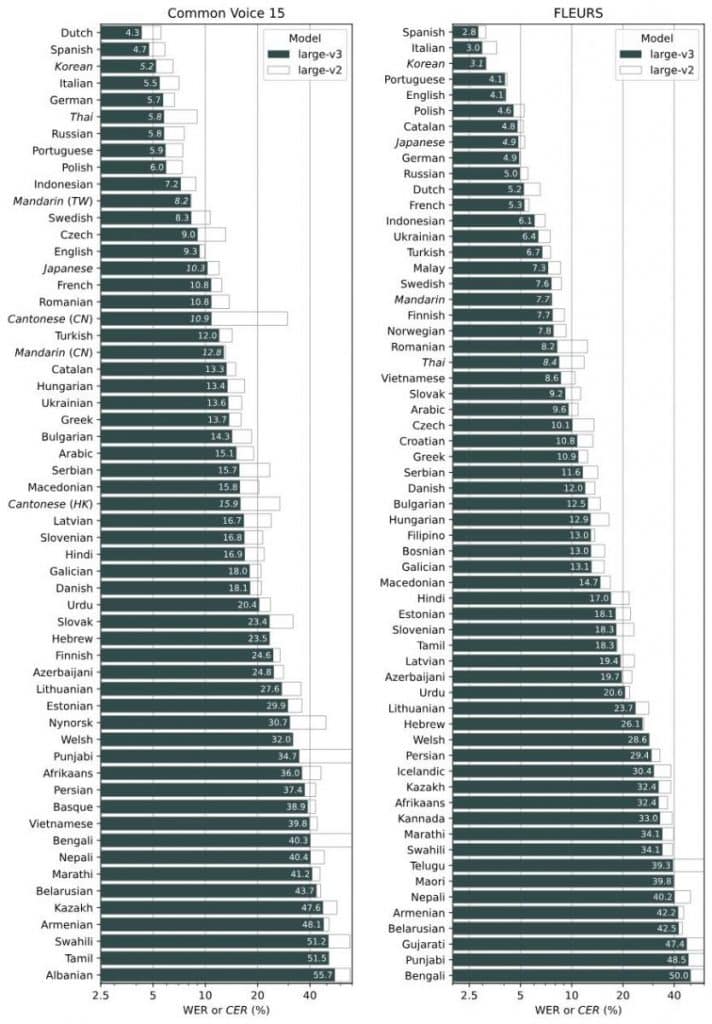
Whisper large-v3 thrives in diverse conditions, adeptly handling various language inputs. According to OpenAI, while models targeting English applications like tiny.en and base.en show superior performance. However, Whisper large-v3’s effectiveness is subject to fluctuation depending on the language being transcribed.
Originally focusing on English upon its launch last September, the model expanded its capabilities with version 2 in December to include support for a range of languages, though it did not specify which ones.
Whisper large-v3 available under a permissive license on GitHub, enables users to transcribe various forms of content with best-in-class accuracy. Its unique timestamp feature adds significant value, potentially revolutionizing subtitle generation on video platforms like YouTube.
OpenAI’s Multilingual Speech Recognition Breakthrough
Whisper large-v3 processes audio by first segmenting it into 30-second clips and then running it through a complex system that includes an encoder and decoder to generate the output.
These components work in unison to predict the textual transcription of the spoken words. One of the technical highlights of Whisper large-v3 is its language identification feature, which not only transcribes multilingual speech but also translates it into English.
While initial plans suggested integration with the popular ChatGPT to facilitate direct voice interaction with the chatbot, OpenAI has opted to grant the public direct access to Whisper large-v3. It’s worth noting that the current target audience for Whisper is primarily researchers, not the general public.
OpenAI’s commitment to advancing robust speech processing is evident in their decision to open-source Whisper large-v3. The organization underscores its objective to foster the development of practical applications and further research in this field.
OpenAI has refined its AI tool with a vast dataset featuring 680,000 hours of closely monitored data gathered from the internet, including a substantial share of non-English audio. This step aims to fuel innovation and broaden the scope of voice recognition technology worldwide.
Disclaimer
Any data, text, or other content on this page is provided as general market information and not as investment advice. Past performance is not necessarily an indicator of future results.
![]()
![]()
The Trust Project is a worldwide group of news organizations working to establish transparency standards.
Nik is an accomplished analyst and writer at Metaverse Post, specializing in delivering cutting-edge insights into the fast-paced world of technology, with a particular emphasis on AI/ML, XR, VR, on-chain analytics, and blockchain development. His articles engage and inform a diverse audience, helping them stay ahead of the technological curve. Possessing a Master’s degree in Economics and Management, Nik has a solid grasp of the nuances of the business world and its intersection with emergent technologies.
Nik Asti

Nik is an accomplished analyst and writer at Metaverse Post, specializing in delivering cutting-edge insights into the fast-paced world of technology, with a particular emphasis on AI/ML, XR, VR, on-chain analytics, and blockchain development. His articles engage and inform a diverse audience, helping them stay ahead of the technological curve. Possessing a Master’s degree in Economics and Management, Nik has a solid grasp of the nuances of the business world and its intersection with emergent technologies.

[ad_2]
Read More: mpost.io






 Bitcoin
Bitcoin  Ethereum
Ethereum  Tether
Tether  XRP
XRP  BNB
BNB  Solana
Solana  USDC
USDC  Dogecoin
Dogecoin  Cardano
Cardano  Wrapped Bitcoin
Wrapped Bitcoin  Hyperliquid
Hyperliquid  Wrapped stETH
Wrapped stETH  Sui
Sui  Bitcoin Cash
Bitcoin Cash  LEO Token
LEO Token  Stellar
Stellar  Avalanche
Avalanche  Toncoin
Toncoin  USDS
USDS  WhiteBIT Coin
WhiteBIT Coin  Shiba Inu
Shiba Inu  WETH
WETH  Wrapped eETH
Wrapped eETH  Litecoin
Litecoin  Binance Bridged USDT (BNB Smart Chain)
Binance Bridged USDT (BNB Smart Chain)  Hedera
Hedera  Ethena USDe
Ethena USDe  Polkadot
Polkadot  Coinbase Wrapped BTC
Coinbase Wrapped BTC  Pepe
Pepe  Pi Network
Pi Network  Aave
Aave  Ethena Staked USDe
Ethena Staked USDe  Bittensor
Bittensor  OKB
OKB  BlackRock USD Institutional Digital Liquidity Fund
BlackRock USD Institutional Digital Liquidity Fund  Aptos
Aptos  NEAR Protocol
NEAR Protocol  Jito Staked SOL
Jito Staked SOL  sUSDS
sUSDS