
[ad_1]

Call out: if you’re an investor who has spent time in this part of the market, I’d love to speak to you!
Okay, so my previous article “How reliable is your node?” got a fair amount of traction and responses. I thought I’d follow it up with another article, this time on the other side of things: pricing and structural market dynamics. I’d recommend reading that before reading this article as it assumes prior knowledge.
RPCs are critical as they are the way we all interact with any blockchain, they basically are the blockchain. Now typically validator nodes are well covered because you can earn an easy 5% on your tokens for clicking a button. Full nodes are a thankless job that don’t get you any incentive (these are what RPCs usually are). If we’re talking about archive nodes, someone better be paying you otherwise you have close to 0 incentive to running one.
Therefore, large companies run these nodes and occupy market share. The market map looks a little something like this:
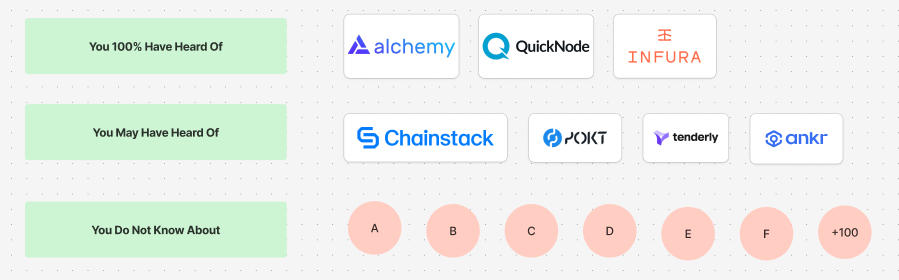
So when you’re an engineer looking for a RPC provider, you usually just go with something you have heard of that works and has a good brand aka the “you 100% have heard of list”. This isn’t lazy, this is a reasonable assumption: “surely the companies that are large and you see all over should be fine”. Well from my previous article, we saw that wasn’t entirely true and there is large variances in performance. In this article we’re going to touch on the economics of this market in its entirety.
Starting off with the: “100%-You-Have-Heard-Of” companies. These are companies are heavily funded and have had money thrown at them by investors over the past few years.
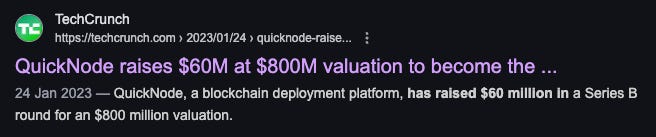

These aren’t small numbers by any means. It is precisely because of this scale of money that you heard of these companies in the first place. Now one would argue that would be a good spend of money in the first place, almost. Granted these companies have many other product lines they’re spinning up, but running nodes is the core of what they do and need to ensure they get right.
The “You May Have Heard Of” companies have come in later and have had to compete and create wedges in the market by offering more chains, ancillary services or purely competing on price. They can play this game and move faster than the larger players because their expense overhead is much smaller: they do not have a $25m-$50m/year payroll to sustain. They can be more experimental and more competitive. However, their biggest challenge is that people haven’t heard of them, and neither do they have the sheer $ resources to compete with the largest players in sales or marketing.
Can’t they compete purely on performance? As I outlined in the prior article, measuring RPC performance is non-existent in the crypto industry and everyone’s in the dark guessing. There are services like Atlas from 1kx that attempt to benchmark these stats but they miss nuances like: tip of chain measurements, sheer RPC load, method level breakdowns, concurrency measurements, node geographies, and most importantly: price RELATIVE to performance. It doesn’t matter if you have the best nodes but they cost 100x more.
I find this segment of the market gets squeezed the most: they do not have strong brands and neither do they have great nodes. They perform somewhere in-between on both of these dimensions.
So if performance isn’t clear, then surely pricing must be. Right? Wrong.
You see, the RPC market has fallen in love with what I call the “Compute Unit” confusion. What you basically do is create a new metrics that customers do not understand, and then force them to understand it — or silently charge more.
Let’s take this simple RPC pricing plan that may or may not be hypothetical.
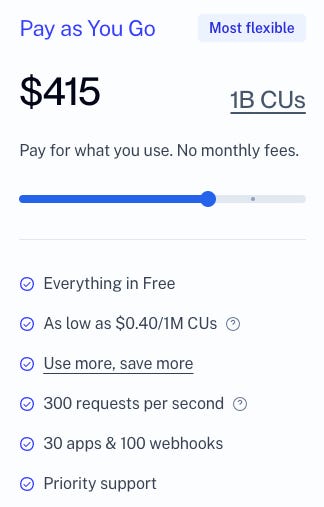
So the first question you ask is, well what is a compute unit?
A compute unit is a measure of how many resources (CPU, RAM, disk, etc) an API method consumes. A simple request like blockNumber only consumes 10 CUs, while a more complex request like eth_call consumes 26 CUs. You can see a full breakdown of our compute units on our docs.
Alright, so what happens when you go to the docs? Well, you get a long list of RPC methods (Ethereum has 70+ alone). However, you also have to factor in what chain you’re on.
So the matrix now becomes:
-
How many compute units do you get per dollar
-
What methods are you calling and figure out how many compute units does it take
-
Apply some multiple based on the chain you’re calling the method (Arbitrum eth_call will cost more CUs than Ethereum eth_call)
Oh also remember that compute unit calculations are different per provider so good luck trying to normalize all of this (unless you’re happy building large quantitative models of your RPC providers’ pricing models).
Surely that’s all you have to keep up with? Not exactly. You see in that screenshot there’s a little bit that says “300 requests per second”. Now if we scroll down on that same page it says the 300 requests are actually 10,000 Compute Units! These are very different things.

Let’s pull up the compute unit pricing table to actually understand this in more detail.

Well turns out there are now two types of compute units, regular compute units and throughput compute units! So if you were doing anything with traces, you’d only need to make 10 debug calls per second to utilize your 10,000 compute unit/second quota! If you’re using something a bit more tame like eth_accounts then sure you’d get 1000 requests/second but you call those methods a lot more often. All this is to say that you have another variable you’re secretly being charged on or being pushed by: throughput.
To recap the levers that go into RPC purchasing decisions:
-
Compute units per dollar
-
Compute units per method
-
Compute units by chain
-
Compute units per second (throughput)
Now here’s the real kicker: all of these can silently be changed without making it look like the price has gone up! We have found that in the past year, our RPC providers have increased costs on us by anywhere from 5x-10x! Yes. You read that right.
Even if you want to use multiple RPCs to avoid getting monopolized, you have to ensure you route your requests intelligently based on a chain/method basis as the pricing between chain/methods between providers can be on the order of 10x. You also have to ensure you build proper financial models constantly tracking different providers’ pricing, which also constantly changes. This also assumes that your second provider supports the chain you’d like to fall back on.
Alright, so why not just use less expensive providers that are cheaper? Well, the reality is that you don’t know what their performance actually is like as stated earlier in the article. These are smaller companies that don’t have the resources of the larger providers so the possibility of failure is much higher and your recourse is far smaller (their brand isn’t in jeopardy as much).
To ensure you can use a smaller provider safely, you need to route failures appropriately. However, routing comes with its own challenges such as:
-
Ensuring you map chains/methods to providers that support the pair
-
Keep up with the prices for your providers and choose intelligently based on the price
-
Understand what is a valid error versus a user failure (the RPC fails versus the RPC request is invalid)
-
Ensuring that a success is actually a success and doesn’t return invalid data
-
Know when to cut off a provider versus waiting for them to succeed
-
Respecting rate limits of whichever provider you’re using when routing
As you can see, what started as a simple problem has very quickly spun out of control with many layers of complexity that need to be tamed. A simple if/else statement won’t suffice due to the above pricing factors alone, you still need to understand performance.
The result of all of this is a RPC market that is inefficient where the top providers gain market share slowly squeezing their top customers like frogs in hot water and those that cannot afford it or need much more reliable services, to build custom solutions to solve all of the above problems.
[ad_2]
Read More: kermankohli.substack.com






 Bitcoin
Bitcoin  Ethereum
Ethereum  Tether
Tether  XRP
XRP  BNB
BNB  Solana
Solana  USDC
USDC  Dogecoin
Dogecoin  Cardano
Cardano  Wrapped Bitcoin
Wrapped Bitcoin  Hyperliquid
Hyperliquid  Wrapped stETH
Wrapped stETH  Sui
Sui  Bitcoin Cash
Bitcoin Cash  LEO Token
LEO Token  Stellar
Stellar  Avalanche
Avalanche  Toncoin
Toncoin  WhiteBIT Coin
WhiteBIT Coin  USDS
USDS  Shiba Inu
Shiba Inu  Wrapped eETH
Wrapped eETH  WETH
WETH  Litecoin
Litecoin  Hedera
Hedera  Binance Bridged USDT (BNB Smart Chain)
Binance Bridged USDT (BNB Smart Chain)  Ethena USDe
Ethena USDe  Polkadot
Polkadot  Coinbase Wrapped BTC
Coinbase Wrapped BTC  Pepe
Pepe  Pi Network
Pi Network  Aave
Aave  Ethena Staked USDe
Ethena Staked USDe  Bittensor
Bittensor  OKB
OKB  Aptos
Aptos  BlackRock USD Institutional Digital Liquidity Fund
BlackRock USD Institutional Digital Liquidity Fund  NEAR Protocol
NEAR Protocol  Jito Staked SOL
Jito Staked SOL  sUSDS
sUSDS