
[ad_1]


In Brief
Google Research and Tel Aviv University have developed AI that combines a text-to-image diffusion with lens geometry for image rendering.
Google Research in collaboration with Tel Aviv University, has introduced a new artificial intelligence (AI) framework that combines a text-to-image diffusion model with specialized lens geometry for image rendering.
This integration allows for precise control over rendering geometry, making it easier to generate diverse visual effects such as fish-eye, panoramic views, and spherical texturing using a single diffusion model.
In a latest research paper, scientists tackled the task of incorporating diverse optical controls into text-to-image diffusion models. This approach involved making the model consider the local lens geometry, enhancing its ability to replicate intricate optical effects and create realistic-looking images.
Instead of merely altering the standard shape of images, this method allows virtually any grid warps through per-pixel coordinate conditioning. This innovative approach supports diverse applications, such as panoramic scene generation that impart a sense of presence and sphere texturing.
Additionally, the framework introduces a manifold geometry-aware image generation framework with metric tensor conditioning. This provides additional possibilities for controlling and modifying the way images are generated, unveiling numerous possibilities for creating and refining pictures.
Precise Image Generation through Text-to-Image Diffusion Integration
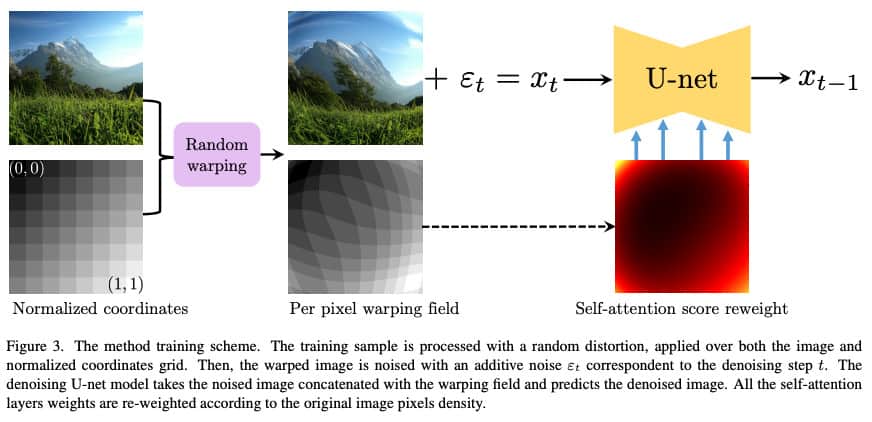
The framework integrates text-to-image diffusion models with specific lens geometry through per-pixel coordinate conditioning. The method entails refining a pre-trained latent diffusion model by utilizing data generated through the distortion of images with random warping fields.
Token reweighting was implemented in self-attention layers, allowing for the manipulation of curvature properties and yielding various effects, such as fish-eye and panoramic views. This approach goes beyond fixed resolution in image generation and includes metric tensor conditioning for improved control.

Revolutionizing Image Manipulation
The framework expands the capabilities of image manipulation, addressing challenges such as large image generation and adjusting self-attention scales in diffusion models.
Effectively, the framework integrates a text-to-image diffusion model with specific lens geometry, allowing for a range of visual effects like fish-eye, panoramic views, and spherical texturing using a single model. It provides meticulous control over curvature properties and rendering geometry, leading to the creation of realistic and nuanced images.
Trained on a substantial textually annotated dataset and per-pixel warping fields, the method produces arbitrary warped images with finely undistorted results closely aligned with the target geometry. Additionally, it facilitates the development of spherical panoramas characterized by realistic proportions and minimal artifacts.

The recently introduced framework, which integrates diverse lens geometries into image rendering, offers improved control over curvature properties and visual effects.
The researchers suggest extending this approach to achieve outcomes comparable to specialized lenses capturing distinct scenes. By considering the potential utilization of more advanced conditioning techniques, the framework envisions enhanced image generation and expanded capabilities.
Disclaimer
In line with the Trust Project guidelines, please note that the information provided on this page is not intended to be and should not be interpreted as legal, tax, investment, financial, or any other form of advice. It is important to only invest what you can afford to lose and to seek independent financial advice if you have any doubts. For further information, we suggest referring to the terms and conditions as well as the help and support pages provided by the issuer or advertiser. MetaversePost is committed to accurate, unbiased reporting, but market conditions are subject to change without notice.
About The Author
Alisa is a reporter for the Metaverse Post. She focuses on investments, AI, metaverse, and everything related to Web3. Alisa has a degree in Business of Art and expertise in Art & Tech. She has developed her passion for journalism through writing for VCs, notable crypto projects, and engagement with scientific writing.
Alisa Davidson

Alisa is a reporter for the Metaverse Post. She focuses on investments, AI, metaverse, and everything related to Web3. Alisa has a degree in Business of Art and expertise in Art & Tech. She has developed her passion for journalism through writing for VCs, notable crypto projects, and engagement with scientific writing.

[ad_2]
Read More: mpost.io






 Bitcoin
Bitcoin  Ethereum
Ethereum  Tether
Tether  XRP
XRP  BNB
BNB  Solana
Solana  USDC
USDC  Dogecoin
Dogecoin  Cardano
Cardano  Wrapped Bitcoin
Wrapped Bitcoin  Hyperliquid
Hyperliquid  Wrapped stETH
Wrapped stETH  Sui
Sui  Bitcoin Cash
Bitcoin Cash  LEO Token
LEO Token  Stellar
Stellar  Avalanche
Avalanche  Toncoin
Toncoin  WhiteBIT Coin
WhiteBIT Coin  USDS
USDS  Shiba Inu
Shiba Inu  WETH
WETH  Wrapped eETH
Wrapped eETH  Litecoin
Litecoin  Binance Bridged USDT (BNB Smart Chain)
Binance Bridged USDT (BNB Smart Chain)  Hedera
Hedera  Ethena USDe
Ethena USDe  Polkadot
Polkadot  Coinbase Wrapped BTC
Coinbase Wrapped BTC  Pepe
Pepe  Pi Network
Pi Network  Aave
Aave  Bittensor
Bittensor  Ethena Staked USDe
Ethena Staked USDe  BlackRock USD Institutional Digital Liquidity Fund
BlackRock USD Institutional Digital Liquidity Fund  OKB
OKB  Aptos
Aptos  NEAR Protocol
NEAR Protocol  Jito Staked SOL
Jito Staked SOL  sUSDS
sUSDS