[ad_1]

The rapid advancements in AI technology have brought forth incredible achievements in natural language processing and image generation. Large language models (LLMs) like GPT-2, GPT-3 (.5), and GPT-4 have demonstrated remarkable performance across various language tasks, while models such as ChatGPT have introduced these language capabilities to the general public. However, as LLMs become more prevalent, and contribute significantly to the language found online, researchers have uncovered a concerning issue known as “model dementia.”

In a recent article, researchers shed light on the phenomenon of model dementia, which refers to the irreversible defects that occur in models when the tails of the original content distribution disappear. The study indicates that using model-generated content during training can lead to this cognitive decline in the resulting models. This effect has been observed in variational autoencoders (VAEs), Gaussian mixture models (GMMs), and LLMs. The findings emphasize the need to address this issue to preserve the benefits of training models on large-scale data obtained from the internet.
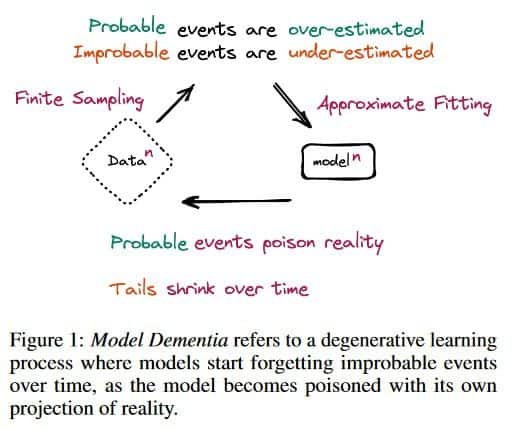
The researchers provide a theoretical understanding of model dementia and demonstrate its prevalence across various generative models. They argue this phenomenon must be taken seriously to ensure the continued effectiveness of training models on extensive web data. As LLMs increasingly contribute to the language and content available online, the value of data collected from genuine human interactions with systems becomes even more critical.
The introduction of stable diffusion, a technique that revolutionized image creation from descriptive text, further exemplifies the impact of LLMs in generating content. However, the study suggests that using model-generated content can cause the loss of tail-end content distribution, potentially eroding the diversity and richness of the original data.
While large-scale data scraped from the web provides valuable insights into human interactions with systems, the presence of content generated by LLMs introduces new challenges. The researchers emphasize the need to address model dementia and find solutions that preserve the benefits of training models on internet data while mitigating the potential loss of original content distribution.
As the field of AI continues to develop, it is crucial for researchers, developers, and policymakers to be aware of the limitations and challenges associated with training models on model-generated content. By understanding and addressing issues like model dementia, we can ensure the responsible and effective use of AI technology in the future.
Read more about AI:
[ad_2]
Read More: mpost.io






 Bitcoin
Bitcoin  Ethereum
Ethereum  Tether
Tether  XRP
XRP  BNB
BNB  Solana
Solana  USDC
USDC  Dogecoin
Dogecoin  Cardano
Cardano  Wrapped Bitcoin
Wrapped Bitcoin  Hyperliquid
Hyperliquid  Wrapped stETH
Wrapped stETH  Sui
Sui  Bitcoin Cash
Bitcoin Cash  LEO Token
LEO Token  Stellar
Stellar  Avalanche
Avalanche  Toncoin
Toncoin  USDS
USDS  WhiteBIT Coin
WhiteBIT Coin  Shiba Inu
Shiba Inu  WETH
WETH  Wrapped eETH
Wrapped eETH  Litecoin
Litecoin  Binance Bridged USDT (BNB Smart Chain)
Binance Bridged USDT (BNB Smart Chain)  Hedera
Hedera  Ethena USDe
Ethena USDe  Polkadot
Polkadot  Coinbase Wrapped BTC
Coinbase Wrapped BTC  Pepe
Pepe  Pi Network
Pi Network  Aave
Aave  Ethena Staked USDe
Ethena Staked USDe  Bittensor
Bittensor  BlackRock USD Institutional Digital Liquidity Fund
BlackRock USD Institutional Digital Liquidity Fund  OKB
OKB  Aptos
Aptos  NEAR Protocol
NEAR Protocol  Jito Staked SOL
Jito Staked SOL  sUSDS
sUSDS