

Deep learning company Deci unveiled DeciCoder, a new generative AI based foundation model that can produce code in various programming languages. According to the company, the model has 1 billion parameters and a large context window of 2048 tokens, which allows it to generate high-quality and diverse code snippets.
Yonatan Geifman, CEO and co-founder of Deci, told Metaverse Post that model inference cost is a major issue for generative AI applications such as code generation. The high cost is mainly due to these model’s size, computational requirements, and memory intensity of the underlying large language models (LLMs). As a result, quick generation necessitates expensive high-end hardware.
“A solution to counteract these exorbitant costs and reduce inference expenditure by 4x is to develop more efficient models,” Geifman told Metaverse Post. “These models should be capable of rapid inference on more affordable hardware without sacrificing accuracy. That’s exactly what DeciCoder does, and it stands out in this regard.”
The company said that when running on NVIDIA’s A10G, a less expensive hardware, DeciCoder’s inference speed surpasses that of SantaCoder, the most popular model in the 1-billion parameter range, running on the pricier NVIDIA’s A100. Moreover, DeciCoder on the A10 is 3.5 times faster than SantaCoder on the A10 and 1.6 times faster than SantaCoder on the A100.
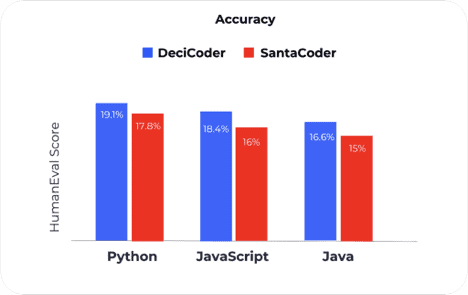
Geifman asserts that DeciCoder also delivers outstanding accuracy. The model outperforms SantaCoder in accuracy across all three programming languages they were both trained on: Python, JavaScript, and Java.
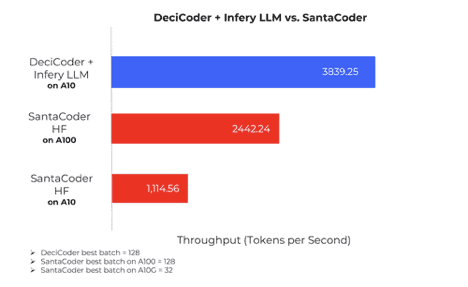
He said that the generative model delivers significantly lower inference costs when used with Deci’s Infery tool: a 71.4% reduction in cost per 1,000 tokens compared to SantaCoder’s performance on the HuggingFace Inference Endpoint.
“DeciCoder reduces computational costs during inference by allowing businesses to migrate their code generation workloads to cheaper hardware without sacrificing speed or accuracy or, alternatively, generate more code in less GPU time,”
Geifman shared.
Furthermore, in conjunction with Infery (Deci’s inference acceleration library) on an A10G GPU, DeciCoder reportedly aids in minimizing carbon footprint. The company asserts that it decreases annual carbon emissions by 324 kg CO2 per model instance compared to SantaCoder on identical hardware.

Advancing Code Generation with Impressive Benchmarks
Geifman explained that two primary technological distinctions are contributing to DeciCoder’s enhanced throughput and reduced memory usage: DeciCoder’s model innovative architecture and the utilization of Deci’s inference acceleration library.
“Deci’s architecture was generated by its proprietary Neural Architecture Search technology, AutoNAC, which has generated multiple high-efficiency foundation models in both computer vision and NLP,” he said. “The intrinsic design of the model architecture endows DeciCoder with superior throughput and accuracy. While DeciCoder, like SantaCoder and OpenAI’s GPT models, is based on the transformer architecture, it diverges in its unique implementation of Grouped Query Attention (GQA).”
GPT-3, SantaCoder, and Starcoder use Multi-Query Attention over Multi-Head Attention for enhanced efficiency, leading to quicker inference. However, this efficiency comes at the cost of reduced quality and accuracy compared to Multi-Head Attention.
Deci’s GQA strikes a superior balance between accuracy and efficiency than Multi-Query Attention. It maintains similar efficiency levels while delivering significantly improved accuracy.
The difference becomes more evident when comparing DeciCoder and SantaCoder, both deployed on HuggingFace Inference Endpoints. DeciCoder achieves a 22% higher throughput and demonstrates improved accuracy, as shown in the second chart and the following chart.
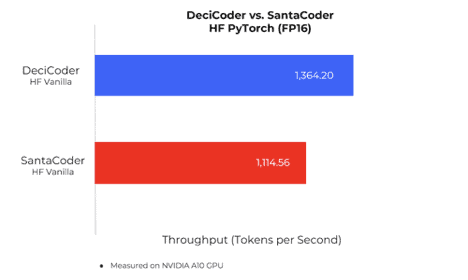
Deci said that its LLM inference acceleration library, Infery, uses advanced proprietary engineering techniques developed by the company’s research and engineering team to accelerate inference.
The company claims that these result in an additional boost in throughput and can be applied to any LLM, other than Deci’s. Moreover, the company said that Infery is comparatively easy to use, allowing developers to employ complex, highly advanced techniques with only a few lines of code.
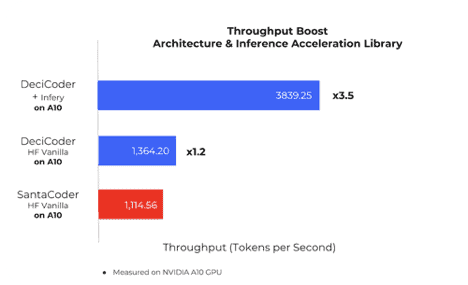
Utilizing AutoNAC For Optimal Balance of Accuracy and Speed
According to Geifman, the quest for the “optimal” neural network architecture has historically been a labor-intensive manual exploration. While this manual approach often yields results, it is highly time-consuming and often falls short of pinpointing the most efficient neural networks.
“The AI community recognized the promise of Neural Architecture Search (NAS) as a potential game-changer, automating the development of superior neural networks. However, the computational demands of traditional NAS methods limited their accessibility to a few organizations with enormous resources,”
Geifman told Metaverse Post.
Deci claims that its “AutoNAC” feature can ease NAS processes by offering a compute-efficient method to produce NAS-generated algorithms, bridging the gap between potential and feasibility.
The company explained that AutoNAC is an algorithm that takes as input specific dataset characteristics, a model task, performance targets, and an inference environment and outputs an optimal neural network that delivers the best balance between accuracy and inference speed for the specified requirements.
In addition to object-detection models such as Yolo-NAS, AutoNAC has already generated transformer-based models for NLP tasks (DeciBert) and computer vision tasks (NAS SegFormer).
The company announced that rollout of DeciCoder is the first in a series of the highly anticipated releases outlining Deci’s Generative AI offering, which are due to be released in the coming weeks.
DeciCoder and its pre-trained weights are now available under the permissive Apache 2.0 License, granting developers broad usage rights and positioning the model for real-world, commercial applications.
Read more:
Read More: mpost.io






 Bitcoin
Bitcoin  Ethereum
Ethereum  Tether
Tether  XRP
XRP  BNB
BNB  Solana
Solana  USDC
USDC  Dogecoin
Dogecoin  Cardano
Cardano  Wrapped Bitcoin
Wrapped Bitcoin  LEO Token
LEO Token  Avalanche
Avalanche  Sui
Sui  Stellar
Stellar  Hedera
Hedera  Shiba Inu
Shiba Inu  Toncoin
Toncoin  USDS
USDS  Wrapped stETH
Wrapped stETH  Bitcoin Cash
Bitcoin Cash  MANTRA
MANTRA  Litecoin
Litecoin  Polkadot
Polkadot  Hyperliquid
Hyperliquid  Binance Bridged USDT (BNB Smart Chain)
Binance Bridged USDT (BNB Smart Chain)  Pi Network
Pi Network  Ethena USDe
Ethena USDe  WETH
WETH  WhiteBIT Coin
WhiteBIT Coin  Wrapped eETH
Wrapped eETH  OKB
OKB  Coinbase Wrapped BTC
Coinbase Wrapped BTC  Pepe
Pepe  Aptos
Aptos  Ondo
Ondo  Gate
Gate  NEAR Protocol
NEAR Protocol  sUSDS
sUSDS  BlackRock USD Institutional Digital Liquidity Fund
BlackRock USD Institutional Digital Liquidity Fund