
Google DeepMind investigated vision-language model applications, focusing on their potential for end-to-end robotic control. This investigation sought to determine whether these models were capable of broad generalisation. Furthermore, it investigated whether certain cognitive functions, such as reasoning and planning, which are frequently associated with expansive language models, could emerge in this context.

The fundamental premise behind this exploration is intrinsically linked to the characteristics of large language models (LLMs). Such models are designed to generate any sequence capable of encoding a vast range of information. This includes not just common language or programming code like Python, but also specific commands that can guide robotic actions.
To put this into perspective, consider the model’s ability to understand and translate specific string sequences into actionable robotic commands. As an illustration, a generated string such as “1 128 91 241 5 101 127 217” can be decoded in the following manner:
- The initial digit, one, signifies that the task is still ongoing and has not reached completion.
- The subsequent triad of numbers, 128-91-241, designates a relative and normalized shift across the three dimensions of space.
- The concluding set, 101-127-217, pinpoints the rotation degree of the robot’s functional arm segment.
Such a configuration enables the robot to modify its state across six degrees of freedom. Drawing a parallel, just as language models assimilate general ideas and concepts from vast textual data on the internet, the RT-2 model extracts knowledge from web-based information to guide robotic actions.
The potential implications of this are significant. If a model is exposed to a curated set of trajectories that essentially indicate, “to achieve a particular outcome, the robot’s gripping mechanism needs to move in a specific manner,” then it stands to reason that the transformer could generate coherent actions in line with this input.
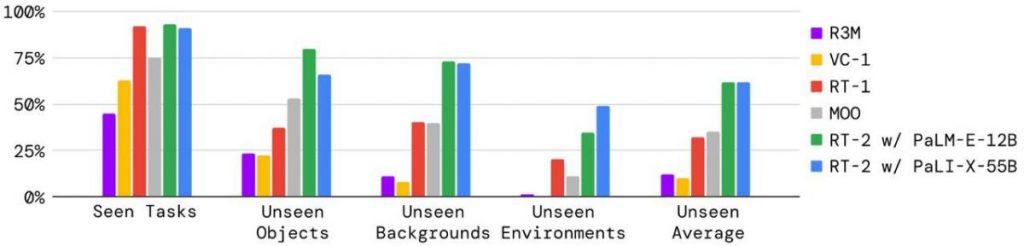
A crucial aspect under evaluation was the capacity to execute novel tasks not covered during training. This can be tested in a few distinct ways:
1) Unfamiliar Objects: Can the model replicate a task when introduced to objects it hasn’t been trained on? Success in this aspect hinges on converting the visual feed from the camera into a vector, which the language model can interpret. The model should then be able to discern its meaning, link a term with its real-world counterpart, and subsequently guide the robotic arm to act accordingly.
2) Different Backgrounds: How does the model respond when the majority of the visual feed consists of new elements because the backdrop of the task’s location has been entirely altered? For instance, a change in tables or even a shift in lighting conditions.
3) Varied Environments: Extending the previous point, what if the entire location itself is different?
For humans, these scenarios seem straightforward – naturally, if someone can discard a can in their room, they should be able to do so outdoors as well, right? (On a side note, I’ve observed a few individuals in parks struggling with this seemingly simple task). Yet, for machinery, these are challenges that remain to be addressed.
Graphical data reveals that the RT-2 model outperforms some of its predecessors when it comes to adapting to these new conditions. This superiority largely stems from leveraging an expansive language model, enriched by the plethora of texts it has processed during its training phase.
One constraint highlighted by the researchers is the model’s inability to adapt to entirely new skills. For instance, it wouldn’t comprehend lifting an object from its left or right side if this hasn’t been part of its training. In contrast, language models like ChatGPT have navigated this hurdle rather effortlessly. By processing vast amounts of data across a myriad of tasks, these models can swiftly decipher and act upon new requests, even if they’ve never encountered them before.
Traditionally, robots have operated using combinations of intricate systems. In these setups, higher-level reasoning systems and foundational manipulation systems often interacted without efficient communication, akin to playing a game of “broken phone”. Imagine conceptualizing an action mentally, then needing to relay that to your body for execution. The newly introduced RT-2 model streamlines this process. It empowers a single language model to undertake sophisticated reasoning while also dispatching direct commands to the robot. It demonstrates that with minimal training data, the robot can carry out activities it hasn’t explicitly learned.
For instance, to enable older systems to discard waste, they required specific training to identify, pick up, and dispose of trash. In contrast, the RT-2 already possesses a fundamental understanding of waste, can recognize it without targeted training, and can dispose of it even without prior instruction on the action. Consider the nuanced question, “what constitutes waste?” This is a challenging concept to formalize. A chip bag or banana peel transitions from being an item to waste post-consumption. Such intricacies don’t need explicit explanation or separate training; RT-2 deciphers them using its inherent understanding and acts accordingly.
Here’s why this advancement is pivotal and its future implications:
- Language models, like RT-2, function as all-encompassing cognitive engines. Their ability to generalize and transfer knowledge across domains means they’re adaptable to varied applications.
- The researchers intentionally didn’t employ the most advanced models for their study, aiming to ensure each model responded within a second (meaning a robotic action frequency of at least 1 Hertz). Hypothetically, integrating a model like GPT-4 and a superior visual model could yield even more compelling results.
- Comprehensive data is still sparse. However, transitioning from the current state to a holistic dataset, ranging from factory production lines to domestic chores, is projected to take about one to two years. This is a tentative estimate, so experts in the field may offer more precision. This influx of data will inevitably drive significant advancements.
- While the RT-2 was developed using a specific technique, numerous other methods exist. The future likely holds a fusion of these methodologies, further enhancing robotic capabilities. One prospective approach could involve training robots using videos of human activities. There’s no need for exclusive recordings – platforms like TikTok and YouTube offer a vast repository of such content.
Read more about AI:
Read More: mpost.io






 Bitcoin
Bitcoin  Ethereum
Ethereum  Tether
Tether  XRP
XRP  BNB
BNB  Solana
Solana  USDC
USDC  Dogecoin
Dogecoin  Cardano
Cardano  Wrapped Bitcoin
Wrapped Bitcoin  Hyperliquid
Hyperliquid  Wrapped stETH
Wrapped stETH  Sui
Sui  Avalanche
Avalanche  Stellar
Stellar  LEO Token
LEO Token  Bitcoin Cash
Bitcoin Cash  Toncoin
Toncoin  Shiba Inu
Shiba Inu  Hedera
Hedera  USDS
USDS  WETH
WETH  Wrapped eETH
Wrapped eETH  Litecoin
Litecoin  Polkadot
Polkadot  Binance Bridged USDT (BNB Smart Chain)
Binance Bridged USDT (BNB Smart Chain)  Ethena USDe
Ethena USDe  Pepe
Pepe  Coinbase Wrapped BTC
Coinbase Wrapped BTC  Pi Network
Pi Network  WhiteBIT Coin
WhiteBIT Coin  Aave
Aave  Bittensor
Bittensor  Ethena Staked USDe
Ethena Staked USDe  OKB
OKB  Aptos
Aptos  NEAR Protocol
NEAR Protocol  BlackRock USD Institutional Digital Liquidity Fund
BlackRock USD Institutional Digital Liquidity Fund  Jito Staked SOL
Jito Staked SOL  Ondo
Ondo